MAGI-1: Autoregressive Video Generation at Scale
Open-Source AI Video Model By Sand AI
Meet MAGI-1, the groundbreaking open-source video generation model from Sand.ai. Leveraging diffusion and autoregression, MAGI-1 delivers exceptional quality, precise control, and real-time streaming, outperforming leading open-source alternatives like Wan-2.1, Hailuo, and HunyuanVideo.
ABOUT MAGI-1
Pioneering Autoregressive AI Video Generation
Innovative Architecture, Superior Results
Autoregressive Approach
MAGI-1 utilizes an autoregressive denoising approach, generating video chunk by chunk (24 frames each). This pipelined design allows simultaneous processing of up to four chunks, enabling efficient streaming generation and seamless extension for longer videos. Trained to denoise per-chunk noise that increases monotonically over time, MAGI-1 enables causal temporal modeling.

Advanced Physics Understanding
Thanks to its architecture, MAGI-1 exhibits a remarkable understanding of physical laws, achieving a Physics-IQ benchmark score of 56.02% – far surpassing existing models in predicting physical behavior and ensuring realistic motion.
Leading Performance & Control
Internal evaluations show MAGI-1 significantly outperforming open-source models like Wan-2.1 and HunyuanVideo. Its instruction following and action quality are highly competitive, rivaling even closed-source commercial models like Kling 1.6. MAGI-1 further supports controllable generation via chunk-wise prompting, enabling smooth scene transitions, long-horizon synthesis, and fine-grained text-driven control.
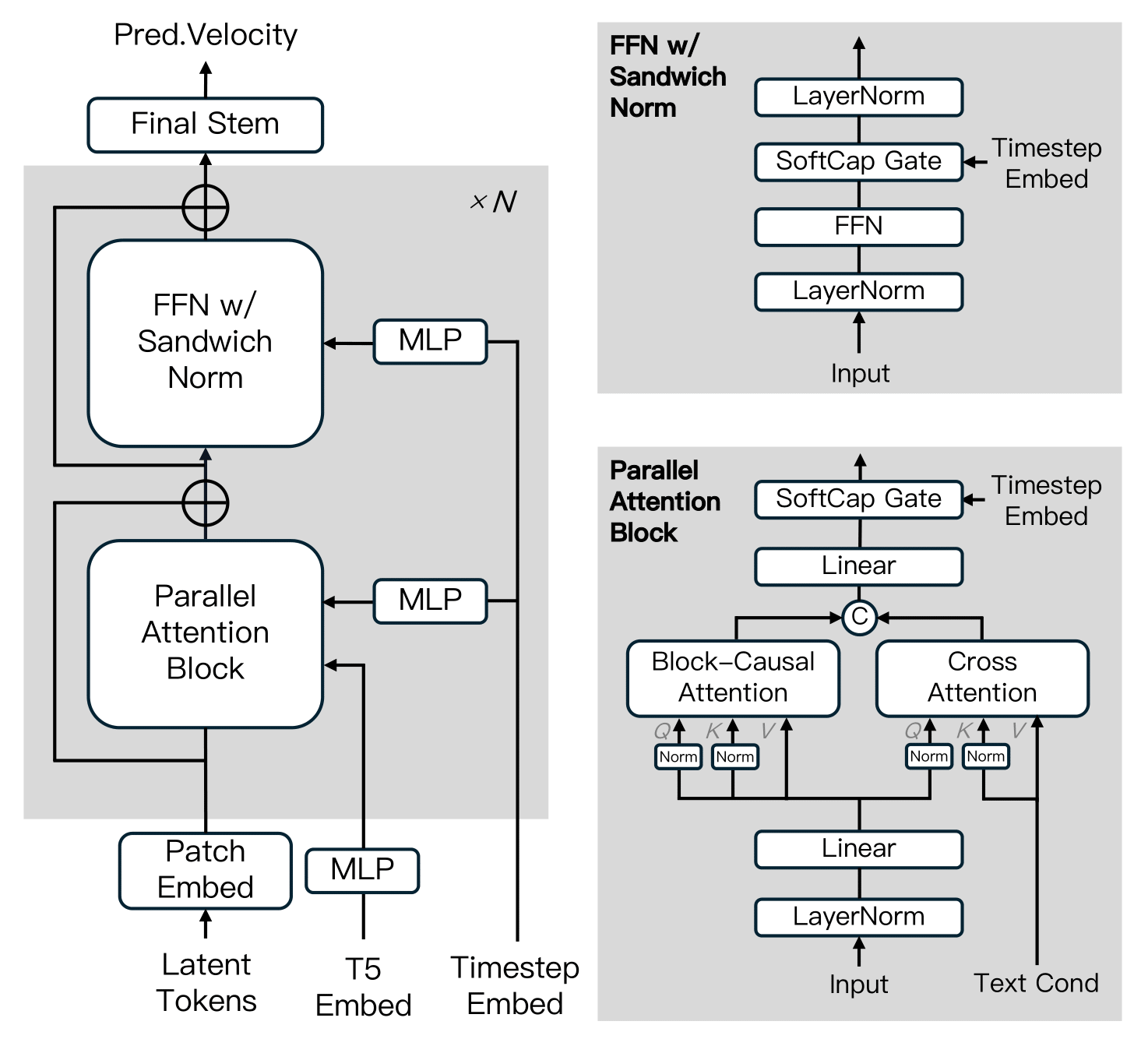
DiT Architecture
MAGI-1's Diffusion Transformer architecture incorporates block-causal attention and parallel processing optimizations, enabling its powerful autoregressive capabilities while maintaining computational efficiency.
We believe MAGI-1 offers a promising direction for unifying high-fidelity video generation with flexible instruction control and real-time deployment.
Fully open-source code and models make MAGI-1 a true game changer, empowering the community with state-of-the-art AI video synthesis.
Top Benchmark Scores
Leading performance vs. open-source models.
Master Quality Video
Exceptional visual fidelity and detail.
High Physics IQ
Superior understanding of physical laws.
Efficient Streaming
Real-time video output via pipelining.
MAGI-1 Technical Features
Delving into the advanced components powering MAGI-1.
High-Performance VAE
MAGI-1 employs a powerful Transformer-based VAE (614M parameters) for efficient video compression. It achieves 8x spatial and 4x temporal compression, surpassing Wan 2.1 in reconstruction quality while offering faster average decoding time than HunyuanVideo due to early spatial downsampling via Conv3D.
Optimized Diffusion Transformer (DiT)
Built upon the DiT framework, MAGI-1 incorporates key improvements for stability, efficiency, and autoregressive modeling:
- Block-Causal Attention: Tailored for autoregressive generation.
- Parallel Attention Block: Enhances training efficiency.
- QK-Norm & GQA: Improve stability and performance.
- Sandwich Normalization & SwiGLU (FFN): Boost model effectiveness.
- Softcap Modulation: Refines conditioning integration.
Utilizes T5 for text feature extraction and sinusoidal embeddings for timesteps. The 24B parameter version is currently open-sourced. (4.5B coming soon!)
Distillation Algorithm
We adopt a shortcut distillation approach training a single velocity-based model for variable inference budgets. By enforcing self-consistency (one large step ≈ two smaller steps), the model approximates flow-matching trajectories across multiple step sizes (cyclically sampled from 8). Classifier-free guidance distillation preserves conditional alignment, enabling efficient inference with minimal fidelity loss. Distilled and quantized models are available.
Model Zoo & Requirements
Access pre-trained weights for MAGI-1 and check hardware recommendations.
| Model | Download Link | Recommended Hardware |
|---|---|---|
| MAGI-1-24B | Hugging Face | H100 / H800 * 8 |
| MAGI-1-24B-distill | Hugging Face | H100 / H800 * 8 |
| MAGI-1-24B-distill+fp8_quant | Hugging Face | H100 / H800 * 4 or RTX 4090 * 8 |
| MAGI-1-4.5B | (Coming Soon - End of April) | RTX 4090 * 1 |
| MAGI-1-VAE | Hugging Face | Included |
| T5 | Hugging Face | Included |
Note: If running the 24B model with RTX 4090 * 8, please set pp_size:2 cp_size: 4 in your configuration.
Evaluation & Benchmarks
MAGI-1 demonstrates state-of-the-art performance in various evaluations.
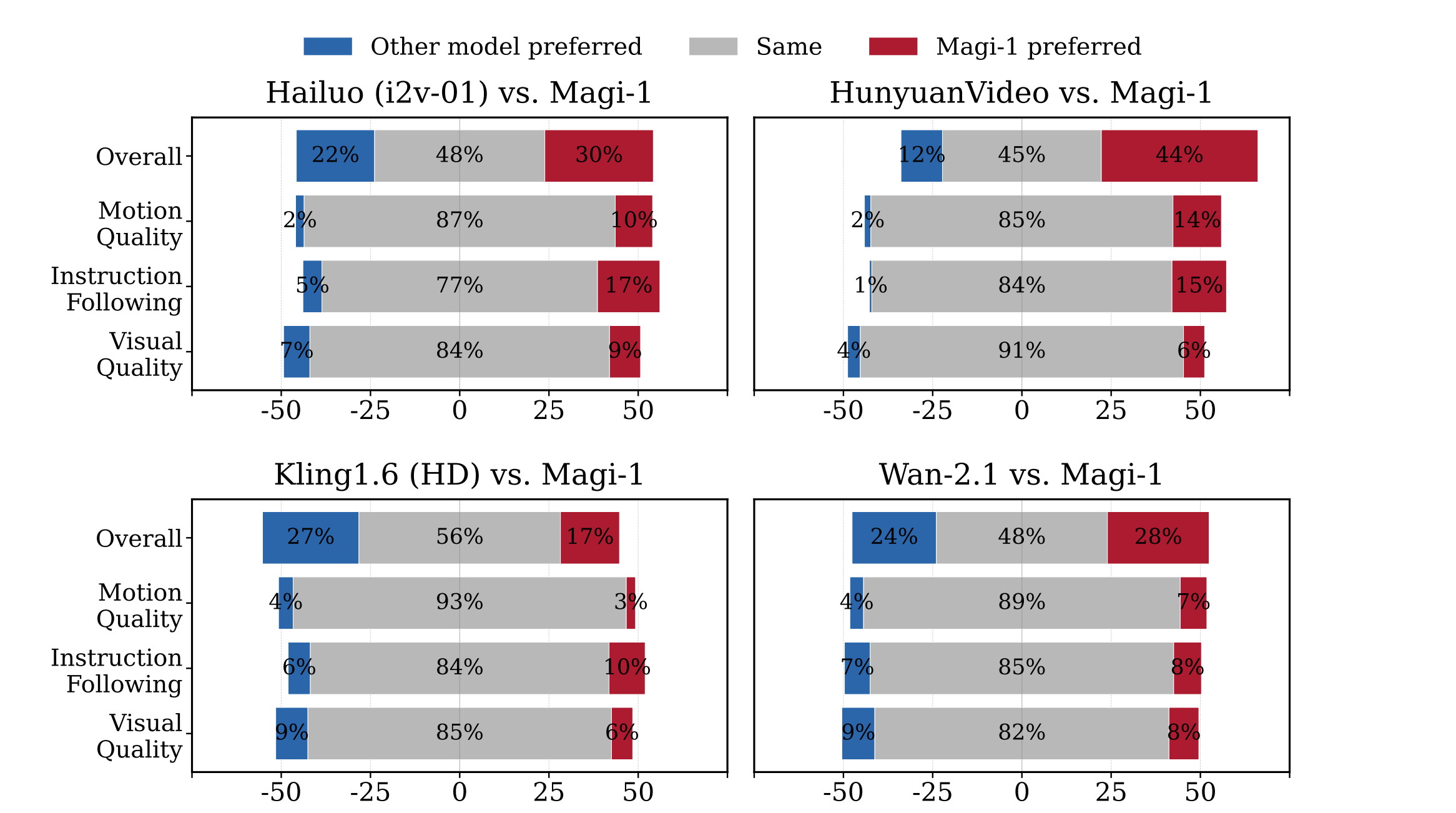
In-house Human Evaluation
MAGI-1 achieves state-of-the-art performance among open-source models like Wan-2.1 and HunyuanVideo, and compares favorably against closed-source models like Hailuo (i2v-01). It particularly excels in instruction following and motion quality, positioning it as a strong potential competitor to commercial models such as Kling.
Physical Evaluation (Physics-IQ)
Thanks to the natural advantages of its autoregressive architecture, MAGI-1 achieves far superior precision in predicting physical behavior on the Physics-IQ benchmark through video continuation—significantly outperforming all existing models.
Physics-IQ Benchmark Scores
| Model | Phys. IQ Score ↑ | Spatial IoU ↑ | Spatio Temporal ↑ | Weighted Spatial IoU ↑ | MSE ↓ |
|---|---|---|---|---|---|
| Magi (V2V) | 56.02 | 0.367 | 0.270 | 0.304 | 0.005 |
| VideoPoet (V2V) | 29.50 | 0.204 | 0.164 | 0.137 | 0.010 |
| Magi (I2V) | 30.23 | 0.203 | 0.151 | 0.154 | 0.012 |
| Kling1.6 (I2V) | 23.64 | 0.197 | 0.086 | 0.144 | 0.025 |
| VideoPoet (I2V) | 20.30 | 0.141 | 0.126 | 0.087 | 0.012 |
| Gen 3 (I2V) | 22.80 | 0.201 | 0.115 | 0.116 | 0.015 |
| Wan2.1 (I2V) | 20.89 | 0.153 | 0.100 | 0.112 | 0.023 |
| Sora (I2V) | 10.00 | 0.138 | 0.047 | 0.063 | 0.030 |
| GroundTruth | 100.0 | 0.678 | 0.535 | 0.577 | 0.002 |
Installation & Usage
Get started with running the MAGI-1 model locally.
Environment Preparation
We provide two ways to set up your environment. Docker is recommended.
1. Docker Environment (Recommended)
docker pull sandai/magi:latest
docker run -it --gpus all --privileged --shm-size=32g \\
--name magi --net=host --ipc=host \\
--ulimit memlock=-1 --ulimit stack=6710886 \\
sandai/magi:latest /bin/bash2. Run with Source Code
# Create a new environment
conda create -n magi python==3.10.12
# Install pytorch (adjust cuda version if needed)
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.4 -c pytorch -c nvidia
# Install other dependencies
pip install -r requirements.txt
# Install ffmpeg
conda install -c conda-forge ffmpeg=4.4
# Install MagiAttention (Refer to its repo for details)
# git clone git@github.com:SandAI-org/MagiAttention.git
# cd MagiAttention
# git submodule update --init --recursive
# pip install --no-build-isolation .Note: Ensure you have Git and Conda installed. Refer to the MagiAttention repository for specific installation details.
Inference Command
Run the MagiPipeline by modifying parameters in the example scripts:
# Run 24B MAGI-1 model
bash example/24B/run.sh
# Run 4.5B MAGI-1 model (when available)
# bash example/4.5B/run.shKey Parameter Descriptions
--config_file: Path to the configuration file (e.g.,example/24B/24B_config.json).--mode: Operation mode:t2v(Text to Video),i2v(Image to Video),v2v(Video to Video).--prompt: Text prompt for generation (e.g.,"Good Boy").--image_path: Path to input image (fori2vmode).--prefix_video_path: Path to prefix video (forv2vmode).--output_path: Path to save the generated video.
Customizing Parameters (Example)
Modify run.sh for different modes:
# Image to Video (i2v)
--mode i2v \\
--image_path example/assets/image.jpeg \\
--prompt "Your prompt here" \\
...
# Video to Video (v2v)
--mode v2v \\
--prefix_video_path example/assets/prefix_video.mp4 \\
--prompt "Your prompt here" \\
...Useful Configs (in config.json)
seed: Random seed for generation.video_size_h/video_size_w: Video dimensions.num_frames: Duration of generated video.fps: Frames per second (4 video frames = 1 latent frame).cfg_number: Use 3 for base model, 1 for distill/quant models.load: Directory containing model checkpoint.t5_pretrained/vae_pretrained: Paths to load T5/VAE models.
Resources & Community
Access the code, models, documentation, and connect with the community.
Technical Report
Dive deep into the architecture, methodology, and benchmark results of the MAGI-1 model.
Open-Source Code
Explore the complete inference code, including the MagiAttention component, on GitHub.
Model Weights (24B+)
Download the open-sourced 24B parameter model weights, plus distilled & quantized versions, from Hugging Face.